
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
The AI race is picking up pace like never before. Following Meta’s move just yesterday to launch its new open source Llama 3.1 as a highly competitive alternative to leading closed-source “frontier” models, French AI startup Mistral has also thrown its had in the ring.
The startup announced the next generation of its flagship open source model with 123 billion parameters: Mistral Large 2. However, in an important caveat, the model is only licensed as “open” for non-commercial research uses, including open weights, allowing third-parties to fine-tune it to their liking.
For those seeking to use it for commercial/enterprise-grade applications, they will need to obtain a separate license and usage agreement from Mistral, as the company states in its blog post and in an X post from research scientist Devendra Singh Chaplot.
While having a lower number of parameters — or internal model settings that guide its performance — than Llama 3.1’s 405 billion, it still nears the former’s performance.
Available on the company’s main platform and via cloud partners, Mistral Large 2 builds on the original Large model and brings advanced multilingual capabilities with improved performance across reasoning, code generation and mathematics.
It is being hailed as a GPT-4 class model with performance closely matching GPT-4o, Llama 3.1-405 and Anthropic’s Claude 3.5 Sonnet across several benchmarks.
Mistral notes the offering continues to “push the boundaries of cost efficiency, speed and performance” while giving users new features, including advanced function calling and retrieval, to build high-performing AI applications.
However, it’s important to note that this isn’t a one-off move designed to cut off the AI hype stirred by Meta or OpenAI. Mistral has been moving aggressively in the domain, raising large rounds, launching new task-specific models (including those for coding and mathematics) and partnering with industry giants to expand its reach.
Mistral Large 2: What to expect?
Back in February, when Mistral launched the original Large model with a context window of 32,000 tokens, it claimed that the offering had “a nuanced understanding of grammar and cultural context” and could reason with and generate text with native fluency across different languages, including English, French, Spanish, German and Italian.
The new version of the model builds on this with a larger 128,000 context window — matching OpenAI’s GPT-4o and GPT-4o mini and Meta’s Llama 3.1.
It further boasts support for dozens of new languages, including the original ones as well as Portuguese, Arabic, Hindi, Russian, Chinese, Japanese and Korean.
Mistral says that the generalist model is ideal for tasks that require large reasoning capabilities or are highly specialized such as synthetic text generation, code generation or RAG.
High performance on third-party benchmarks and improved coding capability
On the Multilingual MMLU benchmark covering different languages, Mistral Large 2 performed on par with Meta’s all-new Llama 3.1-405B while delivering more significant cost benefits due to its smaller size.
“Mistral Large 2 is designed for single-node inference with long-context applications in mind – its size of 123 billion parameters allows it to run at large throughput on a single node,” the company noted in a blog post.


But, that’s not the only benefit.
The original Large model did not do well on coding tasks, which Mistral seems to have remediated after training the latest version on large chunks of code.
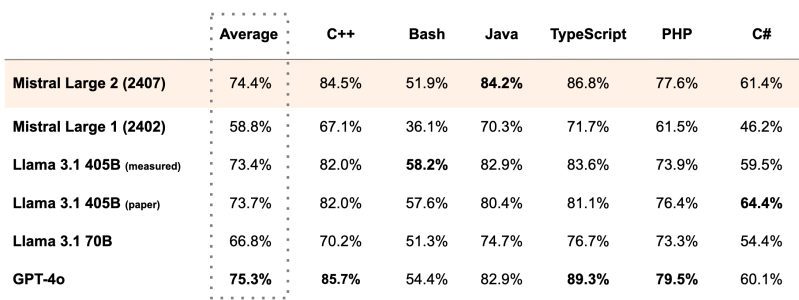
The new model can generate code in 80+ programming languages, including Python, Java, C, C++, JavaScript and Bash, with a very high level of accuracy (according to the average from MultiPL-E benchmark).
On HumanEval and HumanEval Plus benchmarks for code generation, it outperformed Claude 3.5 Sonnet and Claude 3 Opus, while sitting just behind GPT-4o. Similarly, across Mathematics-focused benchmarks – GSM8K and Math Instruct – it grabbed the second spot.


Focus on instruction-following with minimized hallucinations
Given the rise of AI adoption by enterprises, Mistral has also focused on minimizing the hallucination of Mistral Large by fine-tuning the model to be more cautious and selective when responding. If it doesn’t have sufficient information to back an answer, it will simply tell that to the user, ensuring full transparency.
Further, the company has improved the model’s instruction-following capabilities, making it better at following user guidelines and handling long multi-turn conversations. It has even been tuned to provide succinct and to-the-point answers wherever possible — which can come in handy in enterprise settings.
Currently, the company is providing access to Mistral Large 2 through its API endpoint platform as well as via cloud platforms such as Google Vertex AI, Amazon Bedrock, Azure AI Studio and IBM WatsonX. Users can even test it via the company’s chatbot to see how it works in the world.
Source link