
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
There’s a new king in town: Matt Shumer, co-founder and CEO of AI writing startup HyperWrite, today unveiled Reflection 70B, a new large language model (LLM) based on Meta’s open source Llama 3.1-70B Instruct that leverages a new error self-correction technique and boasts superior performance on third-party benchmarks.
As Shumer announced in a post on the social network X, Reflection-70B now appears to be “the world’s top open-source AI model.”
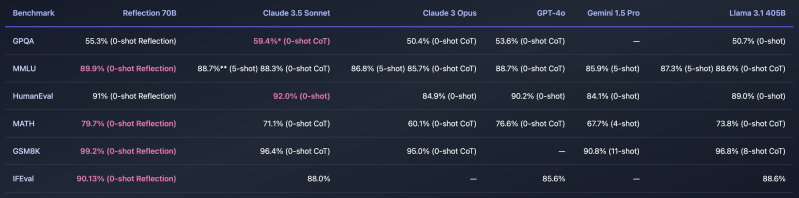
He posted the following chart showing its benchmark performance here:

Reflection 70B has been rigorously tested across several benchmarks, including MMLU and HumanEval, using LMSys’s LLM Decontaminator to ensure the results are free from contamination. These benchmarks show Reflection consistently outperforming models from Meta’s Llama series and competing head-to-head with top commercial models.
You can try it yourself here as a demo on a “playground” website, but as Shumer noted on X, the announcement of the new king of open-source AI models has flooded the demo site with traffic and his team is scrambling to find enough GPUs (graphics processing units, the valuable chips from Nvidia and others used to train and run most generative AI models) to spin up to meet the demand.
How Reflection 70B stands apart
Shumer emphasized that Reflection 70B isn’t just competitive with top-tier models but brings unique capabilities to the table, specifically, error identification and correction.
As Shumer told VentureBeat over DM: “I’ve been thinking about this idea for months now. LLMs hallucinate, but they can’t course-correct. What would happen if you taught an LLM how to recognize and fix its own mistakes?”
Hence the name, “Reflection” — a model that can reflect on its generated text and assess its accuracy before delivering it as outputs to the user.
The model’s advantage lies in a technique called reflection tuning, which allows it to detect errors in its own reasoning and correct them before finalizing a response.
Reflection 70B introduces several new special tokens for reasoning and error correction, making it easier for users to interact with the model in a more structured way. During inference, the model outputs its reasoning within special tags, allowing for real-time corrections if it detects a mistake.
The playground demo site includes suggested prompts for the user to use, asking Reflection 70B how many letter “r” instances there are in the word “Strawberry” and which number is larger, 9.11 or 9.9, two simple problems many AI models — including leading proprietary ones — fail to get right consistently. Our tests of it were slow, but Reflection 70B ultimately provided the correct response after 60+ seconds.

This makes the model particularly useful for tasks requiring high accuracy, as it separates reasoning into distinct steps to improve precision. The model is available for download via the AI code repository Hugging Face, and API access is set to be available later today through GPU service provider Hyperbolic Labs.
An even more powerful, larger model on the way
The release of Reflection 70B is only the beginning of the Reflection series. Shumer has announced that an even larger model, Reflection 405B, will be made available next week.
He also told VentureBeat that HyperWrite is working on integrating the Reflection 70B model into its primary AI writing assistant product.
“We’re exploring a number of ways to integrate the model into HyperWrite — I’ll share more on this soon,” he pledged.
Reflection 405B is expected to outperform even the top closed-source models on the market today. Shumer also said HyperWrite would release a report detailing the training process and benchmarks, providing insights into the innovations that power Reflection models.
The underlying model for Reflection 70B is built on Meta’s Llama 3.1 70B Instruct and uses the stock Llama chat format, ensuring compatibility with existing tools and pipelines.
Shumer credits Glaive for enabling rapid AI model training
A key contributor to Reflection 70B’s success is the synthetic data generated by Glaive, a startup specializing in the creation of use-case-specific datasets.
Glaive’s platform enables the rapid training of small, highly focused language models, helping to democratize access to AI tools. Founded by Dutch engineer Sahil Chaudhary, Glaive focuses on solving one of the biggest bottlenecks in AI development: the availability of high-quality, task-specific data.
Glaive’s approach is to create synthetic datasets tailored to specific needs, allowing companies to fine-tune models quickly and affordably. The company has already demonstrated success with smaller models, such as a 3B parameter model that outperformed many larger open-source alternatives on tasks like HumanEval. Spark Capital led a $3.5 million seed round for Glaive more than a year ago, supporting Sahil’s vision of creating a commoditized AI ecosystem where specialist models can be trained easily for any task.
By leveraging Glaive’s technology, the Reflection team was able to rapidly generate high-quality synthetic data to train Reflection 70B. Shumer credits Sahil and the Glaive AI platform for accelerating the development process, with data generated in hours rather than weeks.
In total, the training process took three weeks, according to Shumer in a direct message to VentureBeat. “We trained five iterations of the model over three weeks,” he wrote. “The dataset is entirely custom, built using Glaive’s synthetic data generation systems.”
HyperWrite is a rare Long Island AI startup
At first glance, it seems like Reflection 70B came from nowhere. But Shumer has been at the AI game for years.
He founded his company, initially called Otherside AI, in 2020 alongside Jason Kuperberg. It was initially based in Melville, New York, a hamlet about an hour’s drive east of New York City on Long Island.
It gained traction around its signature product, HyperWrite, which started as a Chrome extension for consumers to craft emails and responses based on bullet points, but has evolved to handle tasks such as drafting essays, summarizing text, and even organizing emails. HyperWrite counted two million users as of November 2023 and earned the co-founding duo a spot on Forbes‘ annual “30 Under 30” List, ultimately spurring Shumer and Kuperberg and their growing team to change the name of the company to it.
HyperWrite’s latest round, disclosed in March 2023, saw a $2.8 million injection from investors including Madrona Venture Group. With this funding, HyperWrite has introduced new AI-driven features, such as turning web browsers into virtual butlers that can handle tasks ranging from booking flights to finding job candidates on LinkedIn.
Shumer notes that accuracy and safety remain top priorities for HyperWrite, especially as they explore complex automation tasks. The platform is still refining its personal assistant tool by monitoring and making improvements based on user feedback. This cautious approach, similar to the structured reasoning and reflection embedded in Reflection 70B, shows Shumer’s commitment to precision and responsibility in AI development.
What’s next for HyperWrite and the Reflection AI model family?
Looking ahead, Shumer has even bigger plans for the Reflection series. With Reflection 405B set to launch soon, he believes it will surpass the performance of even proprietary or closed-source LLMs such as OpenAI’s GPT-4o, presently the global leader, by a significant margin.
That’s bad news not only for OpenAI — which is reportedly seeking to raise a significant new round of private investment from the likes of Nvidia and Apple — but other closed-source model providers such as Anthropic and even Microsoft.
It appears that once again in the fast-moving gen AI space, the balance of power has shifted.
For now, the release of Reflection 70B marks a significant milestone for open-source AI, giving developers and researchers access to a powerful tool that rivals the capabilities of proprietary models. As AI continues to evolve, Reflection’s unique approach to reasoning and error correction may set a new standard for what open-source models can achieve.
Source link