
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Alibaba Cloud, the cloud services and storage division of the Chinese e-commerce giant, has announced the release of Qwen2-VL, its latest advanced vision-language model designed to enhance visual understanding, video comprehension, and multilingual text-image processing.
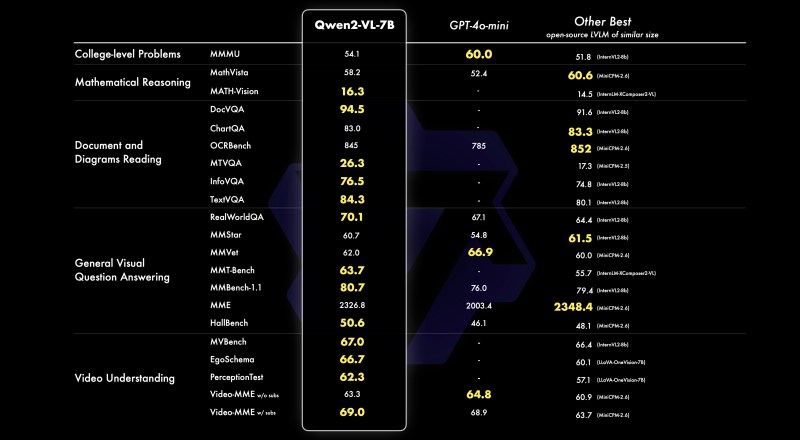
And already, it boasts impressive performance on third-party benchmark tests compared to other leading state-of-the-art models such as Meta’s Llama 3.1, OpenAI’s GPT-4o, Anthropic’s Claude 3 Haiku, and Google’s Gemini-1.5 Flash. You can try an inference of it hosted here on Hugging Face.

Supported languages include English, Chinese, most European languages, Japanese, Korean, Arabic, and Vietnamese.
Exceptional capabilities in analyzing imagery and video, even for live tech support
With the new Qwen-2VL, Alibaba is seeking to set new standards for AI models’ interaction with visual data, including the capability analyze and discern handwriting in multiple languages, identify, describe and distinguish between multiple objects in still images, and even analyze live video in near-realtime, providing summaries or feedback that could open the door it to being used for tech support and other helpful live operations.
As the Qwen research team writes in a blog post on Github about the new Qwen2-VL family of models: “Beyond static images, Qwen2-VL extends its prowess to video content analysis. It can summarize video content, answer questions related to it, and maintain a continuous flow of conversation in real-time, offering live chat support. This functionality allows it to act as a personal assistant, helping users by providing insights and information drawn directly from video content.”
In addition, Alibaba boasts it can analyze videos longer than 20 minutes and answer questions about the contents.
Alibaba even showed off an example of the new model correctly analyzing and describing the following video:
Here’s Qwen-2VL’s summary:
The video begins with a man speaking to the camera, followed by a group of people sitting in a control room. The camera then cuts to two men floating inside a space station, where they are seen speaking to the camera. The men appear to be astronauts, and they are wearing space suits. The space station is filled with various equipment and machinery, and the camera pans around to show the different areas of the station. The men continue to speak to the camera, and they appear to be discussing their mission and the various tasks they are performing. Overall, the video provides a fascinating glimpse into the world of space exploration and the daily lives of astronauts.
Three sizes, two of which are fully open source under Apache 2.0 license
Alibaba’s new model comes in three variants of different parameter sizes — Qwen2-VL-72B (72-billion parameters), Qwen2-VL-7B, and Qwen2-VL-2B. (A reminder that parameters describe the internal settings of a model, with more parameters generally connoting a more powerful and capable model.)
The 7B and 2B variants are available under open source permissive Apache 2.0 licenses, allowing enterprises to use them at will for commercial purposes, making them appealing as options for potential decision-makers. They’re designed to deliver competitive performance at a more accessible scale, and are available on platforms like Hugging Face and ModelScope.
However, the largest 72B model hasn’t yet been released publicly, and will only be made available later through a separate license and application programming interface (API) from Alibaba.
Function calling and human-like visual perception
The Qwen2-VL series is built on the foundation of the Qwen model family, bringing significant advancements in several key areas:
The models can be integrated into devices such as mobile phones and robots, allowing for automated operations based on visual environments and text instructions.
This feature highlights Qwen2-VL’s potential as a powerful tool for tasks that require complex reasoning and decision-making.
In addition, Qwen2-VL supports function calling — integrating with other third-party software, apps and tools — and visual extraction of information from these third-party sources of information. In other words, the model can look at and understand “flight statuses, weather forecasts, or package tracking” which Alibaba says makes it capable of “facilitating interactions similar to human perceptions of the world.”
Qwen2-VL introduces several architectural improvements aimed at enhancing the model’s ability to process and comprehend visual data.
The Naive Dynamic Resolution support allows the models to handle images of varying resolutions, ensuring consistency and accuracy in visual interpretation. Additionally, the Multimodal Rotary Position Embedding (M-ROPE) system enables the models to simultaneously capture and integrate positional information across text, images, and videos.
What’s next for the Qwen Team?
Alibaba’s Qwen Team is committed to further advancing the capabilities of vision-language models, building on the success of Qwen2-VL with plans to integrate additional modalities and enhance the models’ utility across a broader range of applications.
The Qwen2-VL models are now available for use, and the Qwen Team encourages developers and researchers to explore the potential of these cutting-edge tools.
Source link